Quickstart
A quick dive into getting started with Lore
A quick dive into getting started with Lore
In this section we'll learn how to normalize an API responses, so that we can reduce the number of network requests and improve the application's performance.
At the end of this section your application will look like this (visually identical):
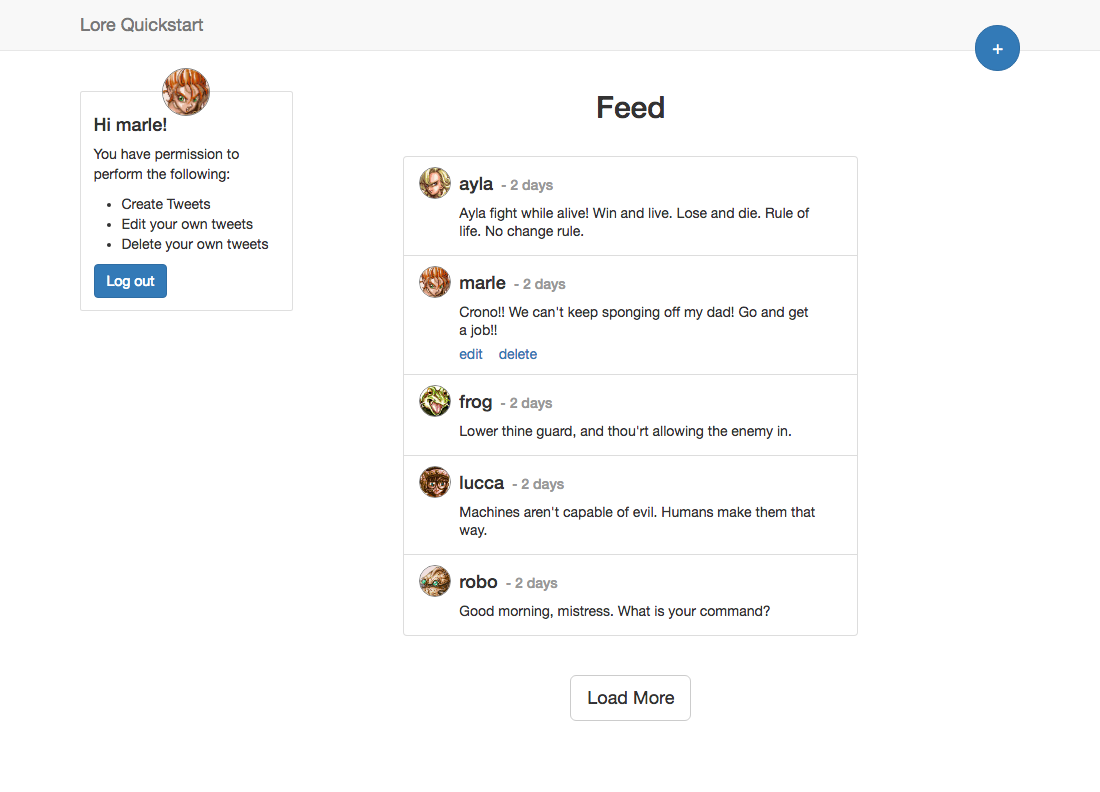
If you open the browser developers tools and take a look at the network requests when the Feed page loads, you'll see a series of AJAX calls being made to the API that look something like this:
[1] XHR finished loading: GET "http://localhost:1337/user"
[2] XHR finished loading: GET "http://localhost:1337/tweets?page=1"
[3] XHR finished loading: GET "http://localhost:1337/users/1"
[4] XHR finished loading: GET "http://localhost:1337/users/2"
[5] XHR finished loading: GET "http://localhost:1337/users/3"
[6] XHR finished loading: GET "http://localhost:1337/users/4"
The first API call retrieves the current user (Marle). The second retrieves the first page of tweets, and the remaining calls retrieve the user who created each of those tweets so that we can get their nickname and avatar. So that's 6 API calls to display 5 tweets.
Now imagine you have a page that displays 20 tweets, and each tweet is by a different user. If we change nothing about how the application requests data, that would amount to 22 API calls just to display the first page of tweets; 1 for the current user, 1 for the first page of tweets, and 20 to fetch the user that created each tweet.
That means we'd need to wait for 22 network requests to return before the experience can be displayed as intended, and displaying the second page might require another 21 network requests.
That's certainly a cause for concern, as it's not hard to see how that can become a performance issue for both the browser and server, but it turns out the problem is even worse than that, because every browser limits the number of concurrent requests to a single domain.
To illustrate, take a look at the table below showing the concurrent request limits for various browsers:
Concurrent Connections Per Hostname
Chrome 57 6
Firefox 46 6
Safari 10 6
IE 10 8
IE 11 13
If our hostname is localhost:1337, what this table tells us is that Chrome 57 will only allow 6 API calls to be issued to that domain at a single time. This means that if we make 20 network requests to retrieve the users for 20 tweets, the browser will only send 6 requests, and then queue the other 14. Once one of the 6 comes back, the browser will send out one of the queued requests.
Especially for APIs with slow response times, this can wreak all kinds of havoc on the user experience and responsiveness of the application.
When we make an API call to http://localhost:1337/tweets currently, we get a response back that looks like this:
{
data: [
{
id: 1,
user: 418,
text: "Ayla fight while alive! Win and live. Lose and die. Rule of life. No change rule.",
createdAt: "2017-05-06T16:20:15.439Z",
updatedAt: "2017-05-06T19:20:15.455Z"
}
],
meta: {
paginate: {
currentPage: 1,
nextPage: null,
prevPage: null,
totalPages: 1,
totalCount: 1,
perPage: 5
}
}
}
And then then we make another request to http://localhost:1337/users/1 to get the user, which returns a response like this:
{
id: 418,
nickname: "ayla",
authId: "auth0|57f1e2ad68e2b55a013258cd",
avatar: "https://cloud.githubusercontent.com/assets/2637399/19027069/a356e82a-88e1-11e6-87d8-e3e74f55c069.png",
createdAt: "2017-05-06T19:20:15.431Z",
updatedAt: "2017-05-06T19:20:15.431Z"
}
Since we know we need the user for each tweet, one way to solve the aforementioned problem is to ask the API to embed the user data inside the tweet, so that we can learn who the user is without making a follow-up request.
The Sails API supports the ability to do this by providing a query parameter called populate that lists the relationships you want populated. For example, if you want the API to populate the user field, you can make a request to http://localhost:1337/tweets?populate=user, and you'll see a response like this:
{
data: [
{
id: 1,
user: {
id: 418,
nickname: "ayla",
authId: "auth0|57f1e2ad68e2b55a013258cd",
avatar: "https://cloud.githubusercontent.com/assets/2637399/19027069/a356e82a-88e1-11e6-87d8-e3e74f55c069.png",
createdAt: "2017-05-06T19:20:15.431Z",
updatedAt: "2017-05-06T19:20:15.431Z"
},
text: "Ayla fight while alive! Win and live. Lose and die. Rule of life. No change rule.",
createdAt: "2017-05-06T16:20:15.439Z",
updatedAt: "2017-05-06T19:20:15.455Z"
}
],
meta: {
paginate: {
currentPage: 1,
nextPage: null,
prevPage: null,
totalPages: 1,
totalCount: 1,
perPage: 5
}
}
}
By requesting that the API populate the user field for each each tweet, we can reduce the number of API calls required to get all the data we need from 22 requests to 2 requests, and it's always going to be 2 requests regardless of the number of tweets we request per page.
The downside of requesting nested data from an API is that it's not a good idea to use it directly in your application. Not only can you easily run into issues keeping the data in-sync, by not having a clear "source of truth", but it also makes your application more sensitive to changes in the API, since the components in your application begin to assume a nested data structure.
To avoid these issues entirely, it's recommended that instead of storing that data as a tweet that contain the user, you instead break apart the API response and store the tweet and user separately, exactly as you would have before nesting the data.
This process is called normalization and is something Lore provides support for by default.
Ready? Let's get started!